![[Paper Review] Asymmetric inter-intra domain alignments (AIIDA) method for intelligent fault diagnosis of rotating machinery](/assets/images/PaperReview_AIIDA/aiidafoot.jpg)
[Paper Review] Asymmetric inter-intra domain alignments (AIIDA) method for intelligent fault diagnosis of rotating machinery
The second paper I will review is ‘Asymmetric inter-intra domain alignments (AIIDA) method for intelligent fault diagnosis of rotating machinery’ written by Ph.D. candidate Jinwook Lee from SNU HAI Lab.
> Introduction
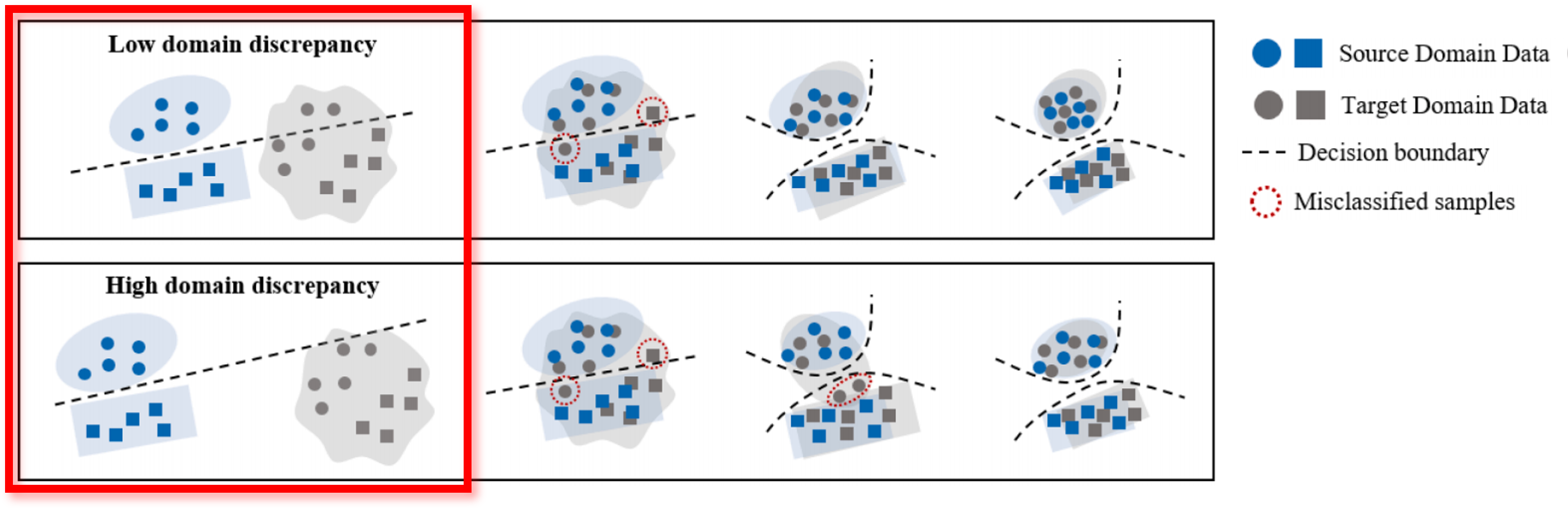
Conventional methods, such as machine learning, diagnose faults by extracting features through signal processing, requiring significant domain expertise and struggling with large datasets. In contrast, deep learning methods need less domain knowledge and can handle large datasets more efficiently. However, they require a substantial amount of labeled data and depend on consistent data distribution to perform well.
As seen in the upper image within the red box, conventional DL-based approaches fail to train a robust fault diagnosis model with high generalization performance. Additionally, as shown in the lower image within the red box, the classification performance further deteriorates as domain shifts increase with greater variability.
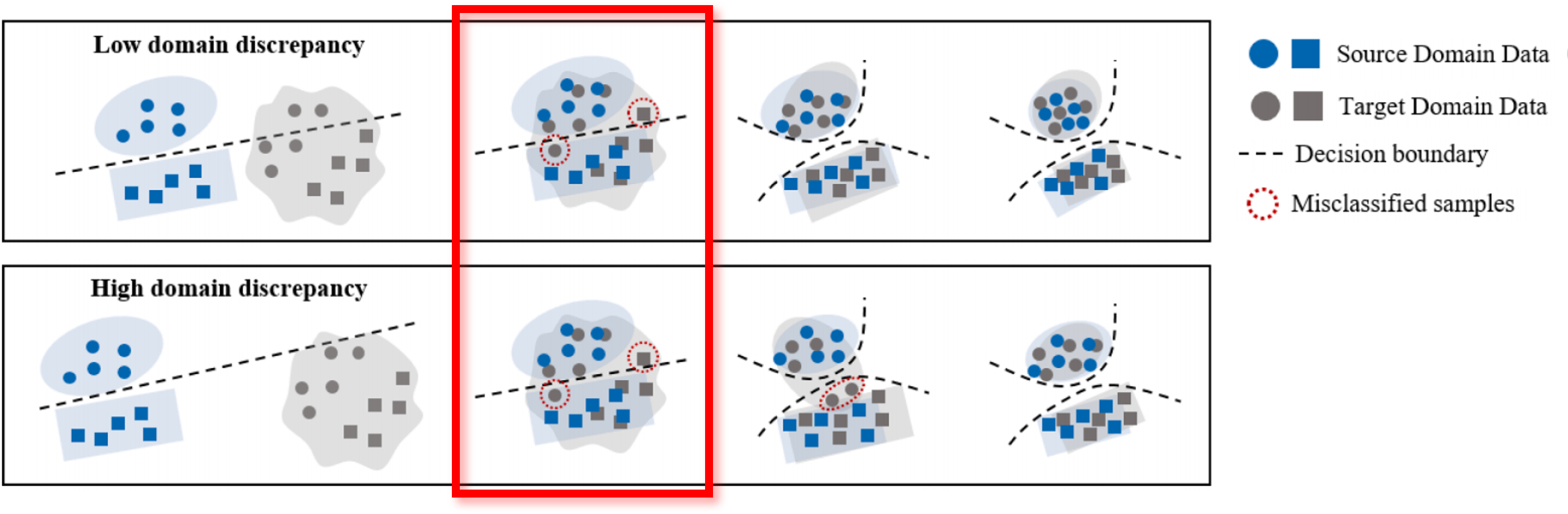
Unsupervised domain adaptation (UDA), which transfers knowledge from the labeled source domain to the unlabeled target domain, offers a promising solution to address this problem. The main idea is to learn feature mapping, which makes the source and target domain have shared representation by minimizing the discrepancy between the two domains. But they only align the marginal distributions of the source and target domains and class-conditional distributions of the two domains are not aligned. In the red box, as indicated by the red dashed lines, misclassified samples near the decision boundary of the classifier lead to decreased diagnosis performance in the target domain.
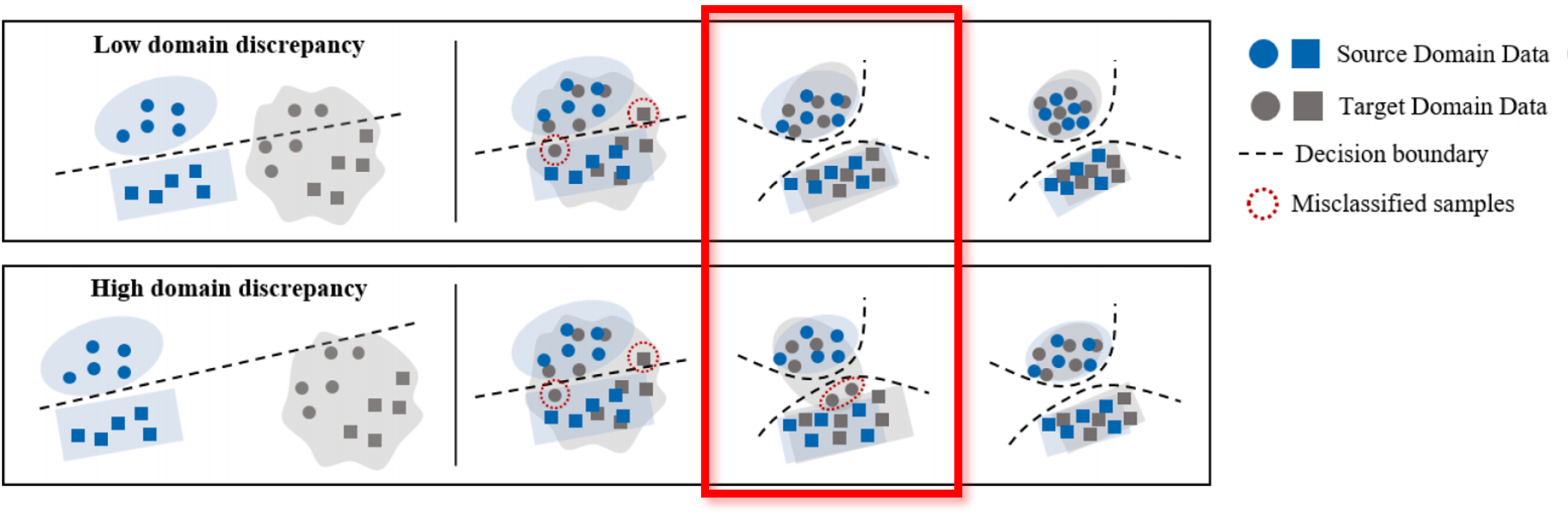
To address this problem, the method based on Adversarial Classifier was proposed. Two label classifiers are exploited to detect target samples far from source samples. Detected target features are trained to be generated inside decision boundaries of label classifiers by adversarial training. As the domain discrepancy increases, the performance for the target domain drops sharply. Both the stability of the training and convergence speeds are low, due to the training strategy of this method.
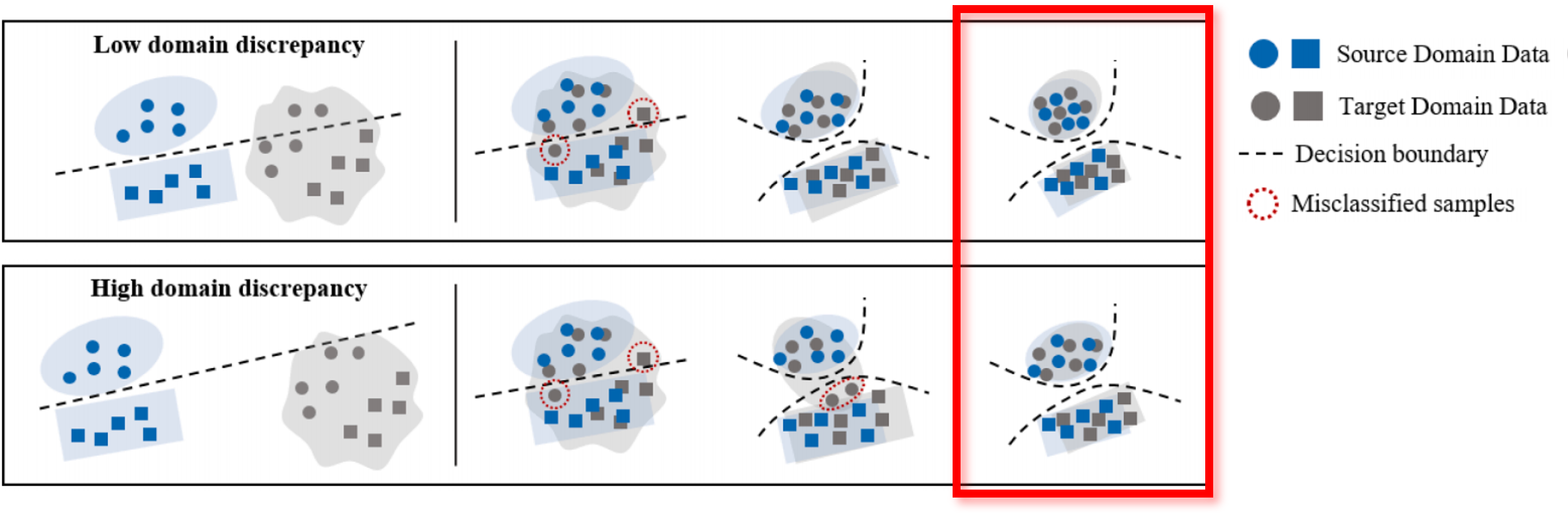
Asymmetric inter-intra domain alignments (AIIDA) method for fault diagnosis of rotating machinery is proposed to address these problems.vSource feature extractor and classifiers are trained to classify source domain data correctly. Marginal distributions are aligned by minimizing MMD and domain adversarial loss simultaneously,making the source and target features closer to each other globally.
> Theoretical Background
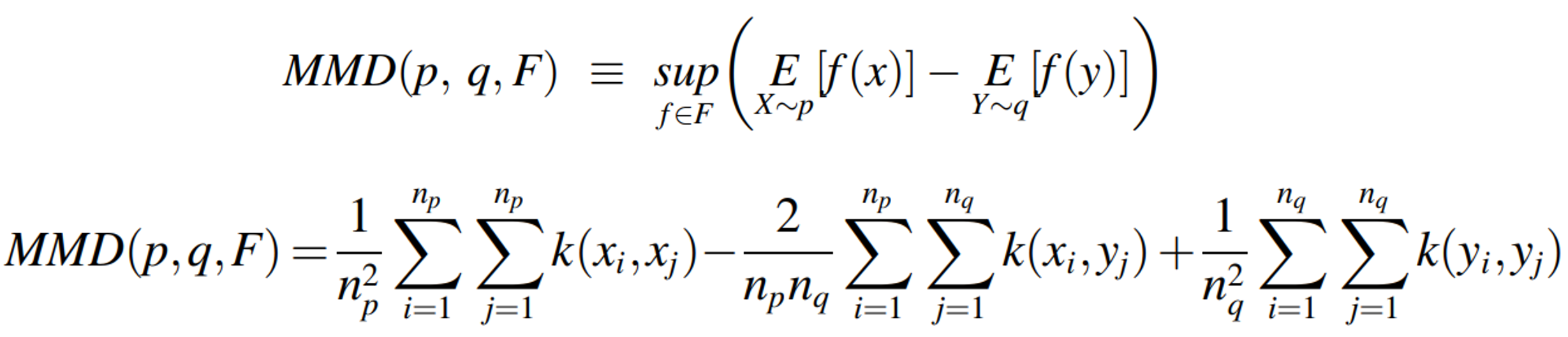
MMD is the maximum difference between the expectation of kernel embeddings of two probability distributions in the Reproducing Kernel Hilbert Space (RKHS).
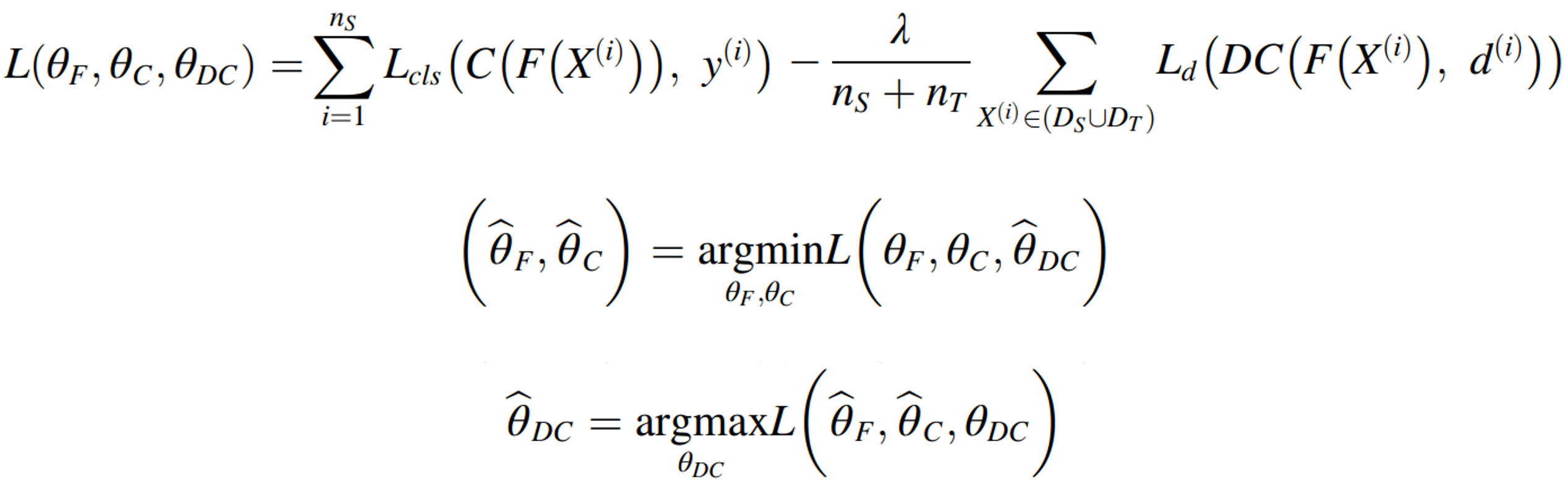
The concept of GAN is adopted to extract domain-invariant features. Through adversarial training between F and DC, domain invariant features are learned because the source and target features are projected into the same region in the high-level feature space. Discriminative features for the source domain are learned by adopting supervised learning with F and C. Based on the learned features, the model can generalize well to the unlabeled target domain.
> Proposed Method
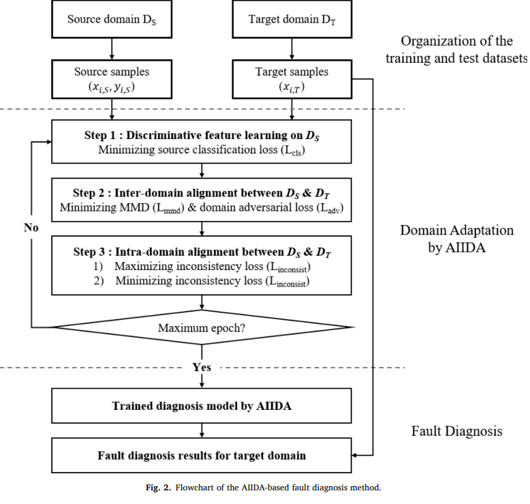
The following is the flowchart.
The following is the architecture.
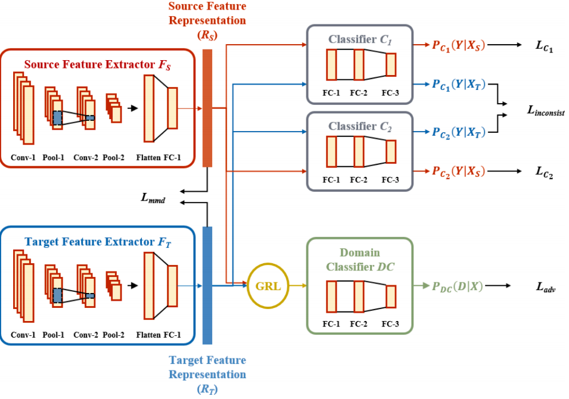

Most previously studied approaches learn feature representation by using a symmetric feature extractor, where the source and target feature extractors have the same architecture and share the weights. However, by concentrating only on learning shared representation between the two domains through symmetric mapping, individual characteristics of each domain are ignored, which is detrimental to the discriminative power of the model for the target domain. In theory, asymmetric mapping can lead to more effective adaptation since the inherent nature of each domain is explicitly modeled to extract domain-invariant features.

Feature extractor and classifiers are trained to classify the label of the source samples correctly. As a result, decision boundaries of label classifiers are trained to correctly classify source domain data. It is very important to learn discriminative features for the source domain, because the target domain error is bounded by the source classification error and domain discrepancy in the UDA task.
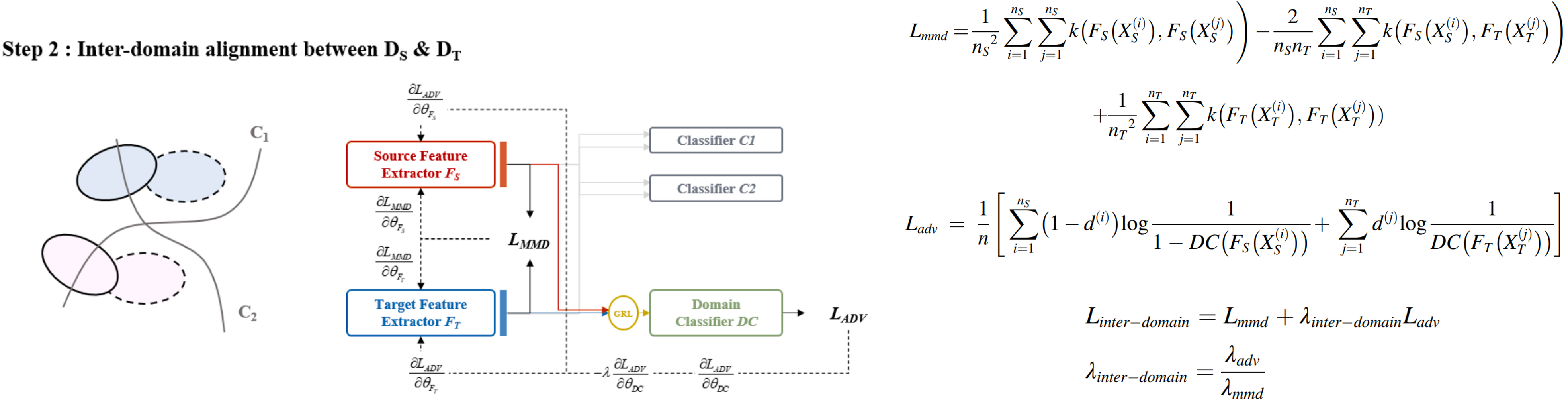
The marginal distributions of the source and target domains are aligned by minimizing the domain discrepancy. Reduce the discrepancy between the source and target domains stably and effectively by using both methods (minimizing the domain discrepancy using the statistically defined distance & utilizing an adversarial training scheme).
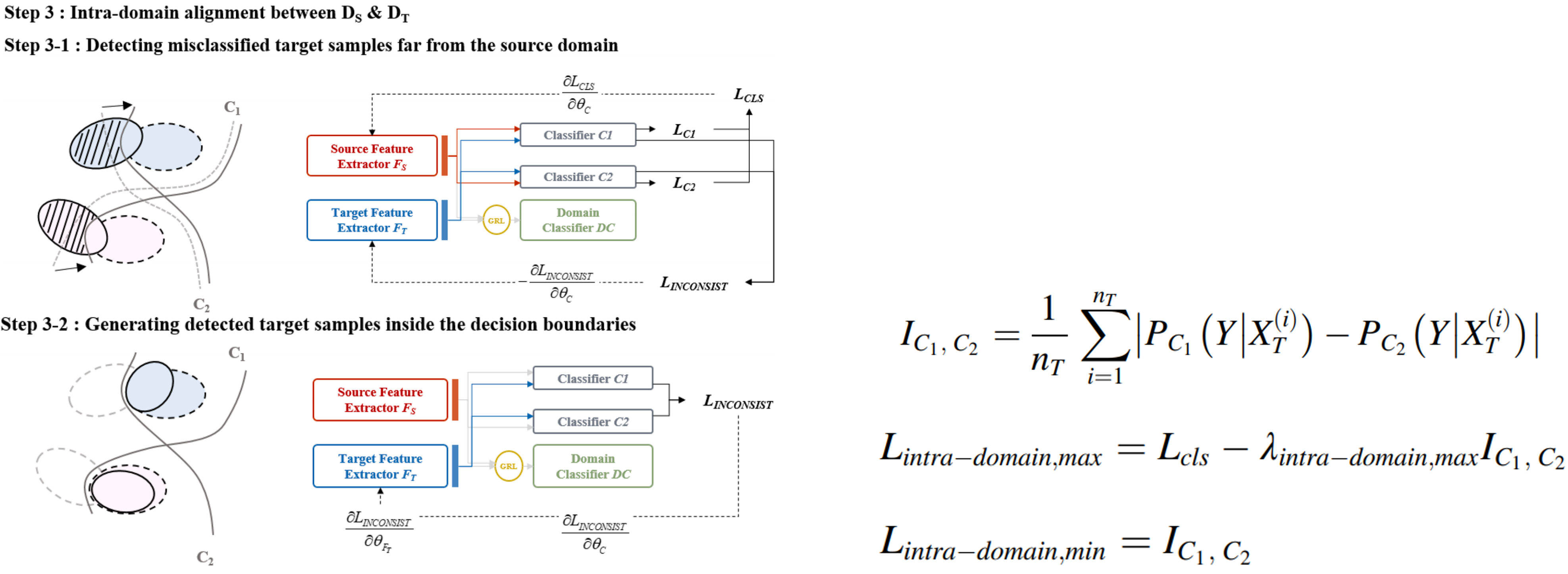
Since there is no label information for the target domain in UDA, it is impossible to align the class-conditional distribution. Use the inconsistency between two label classifiers, which represents the target domain region that is misclassified by the two label classifiers.
> Result and Analysis

CWRU, SHRM, IMS are used for validation. Also, total 7 compared models are used.
1) Source Only: Only trained to minimize classification loss for the source domain data (no DA)
2) MMD: The architecture is the same as that of SO, except that additional MMD loss is adopted to minimize the distribution discrepancy between the source and target features
3) DANN: The domain classifier is added behind the feature extractor, where domain adversarial loss is adopted to play the same role as the MMD loss in the previous method
4) IntraD: An additional classifier is added behind the feature extractor
Inconsistency is calculated from the outputs of 2 classifiers and utilized to match the distributions of each class in both domains
5) DCTLN: Both domain-adversarial loss and MMD loss are adopted to minimize the domain discrepancy between the source and target domains
6) DASC: Additional semantic clustering loss is adopted in multiple feature levels to make samples better semantically clustered, according to their classes
7) SIIDA: Same as the proposed method, except for its use of a symmetric feature extractor. To show the abilities of an asymmetric feature extractor to stabilize the training procedure and offer perfect matching between the source and target domains, which is not feasible with a symmetric feature extractor
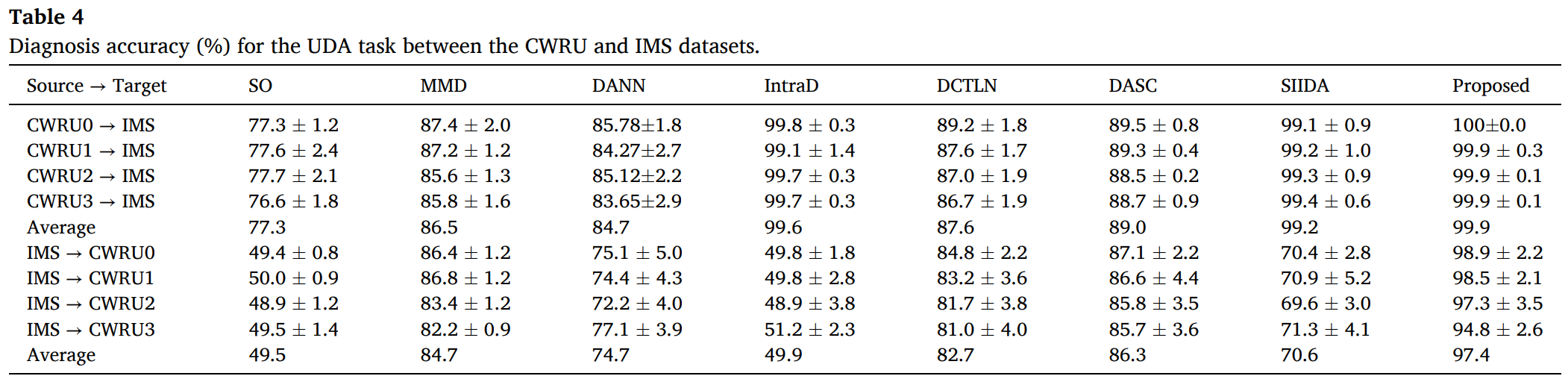
From the Table 4, we can derive 8 conclusions.
1) All UDA algorithms show performance improvement, as compared with the SO method
2) Task of IMS→CWRU is more complicated than that of CWRU→IMS
3) MMD shows better results than DANN
4) Consideration of class-conditional distribution alignment alone is not enough when large domain discrepancy exists
5) DCTLN yields performance similar to MMD and DANN, but shows lower standard deviation than DANN
6) DASC, SIIDA and AIIDA generally yield better results than other methods
7) DASC yields poor results compared to IntraD, SIIDA yields poor results compared to marginal DANN and MMD
8) AIIDA approach produces the best classification performance for all cases
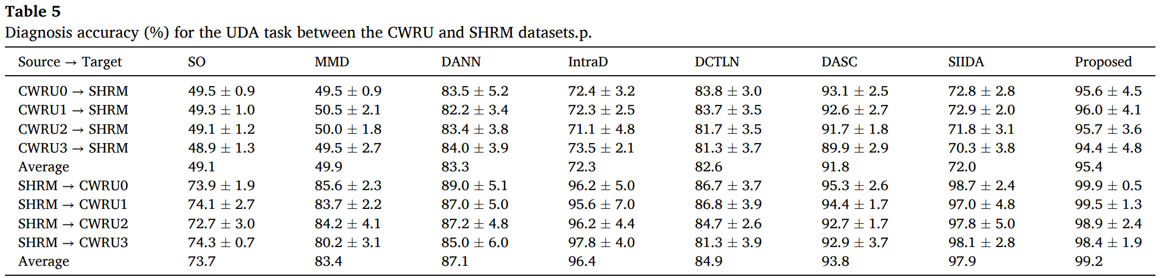
And from the Table 5, we can derive 2 conclusions.
1) DANN shows better results than MMD (opposite of the results found in the previous task)
2) AIIDA approach achieves the best classification performance for all cases

t-SNE is used to visualize the high-dimensional data by embedding the n-D original feature space into 2-D space. From this visualization, we can derive 4 conclusions.
1) Except IntraD, marginal distributions of different domains are closer, as compared with the SO approach
2) DCTLN learns more generalized features than those learned by DANN and MMD
3) IntraD intuitively seems to show poor results; however, this is due to the difference in learning strategy between the marginal and class-conditional distribution alignment approaches
4) DASC, SIIDA, and AIIDA approaches learn better representations than other marginal or classconditional distribution alignment methods, as shown in Fig. 7(e), (g) and (h)
> Conclusion
To extract features that are domain-invariant and class-wise discriminative for superior adaptation performance, both the marginal and class-conditional distributions between two domains are aligned. Asymmetric feature extractor is adopted to better capture the characteristics of different domains and stabilize the training process. AIIDA shows higher target accuracy than any of the compared methods in all scenarios studied. Visualization results of the learned features confirm that the proposed method is superior to other compared methods.
Calendar
